前言
最近因为搞paper的需求,要看一些有关声学、波、调制的一些背景知识,暂时收集于此。
参考资料:
- https://www.bilibili.com/video/BV1xt411y7dT?t=4762 MIT 振动和波 公开课(需要一点微积分和物理基础,老师很敬业会做很多有意思的实验)
- https://www.cnblogs.com/BaroC/p/4283380.html MFCC
正文
暂时记录一些数据或实验结果之类……暂时还没有系统学一些东西。
对我的华为手机进行测试,使用”你好荣耀”做唤醒命令。测试显示将我的语音做5kHz的低通滤波依旧可以唤醒手机。
MFCC
在Paper中多次看到了MFCC这个概念。Mel Frequency Cepstrum Coefficient, MFCC。抽象的来讲,这是一种表现一段音频特征(尤其是语音特征)的一个向量。我们可以通过系统的流程算出一段音频的MFCC,并以此来进行特征的匹配。
原理
这一部分主要参考了 https://www.cnblogs.com/BaroC/p/4283380.html,需要一些通信原理的知识阅读,脉络还是蛮清晰的。一些复杂的地方也没有深挖。
因为参考链接中对MFCC为什么这样提取已经做了较详细的介绍,并且逻辑很清晰,这里就不再赘述。对一些关键概念在这里稍作记录。
倒谱分析(Cepstrum Analysis):将原信号经过傅里叶变换得到频谱,然后取对数,再做逆傅里叶变换。
Mel频率分析(Mel-Frequency Analysis):因为人类对音高的感知并不和整个自然线性频率一致,就像是有很多滤波器组一样。Mel频率分析就是对原来频率做处理映射到Mel非线性频率上,尽可能模拟人耳听觉特征。人耳对于语音特征的提取具有非常强大的能力,所以使用Mel频率分析可以更好的把握人声特征等信息。下面是将普通频率转化到Mel频率的公式。
$$
mel(f) = 2595 * log_{10}(1+f/700)
$$
那么顺序过一下MFCC的流程如下。
- 预加重:https://www.zhihu.com/question/49853988 本质是加强高频信号,增强辅音信息。
- 分帧:https://blog.csdn.net/class_brick/article/details/82743741 先将N个采样点集合成一个观测单位,称为帧。通常情况下N的值为256或512,涵盖的时间约为20~30ms左右。为了避免相邻两帧的变化过大,因此会让两相邻帧之间有一段重叠区域,此重叠区域包含了M个取样点,通常M的值约为N的1/2或1/3。通常语音识别所采用语音信号的采样频率为8KHz或16KHz,以8KHz来说,若帧长度为256个采样点,则对应的时间长度是256/8000 1000=32ms。
- 加窗: 这里目的是消除各个帧两端可能会造成的信号不连续性。(看不透了)。这里将每一帧代入窗函数,窗外的值设定为0,其目的是消除各个帧两端可能会造成的信号不连续性。常用的窗函数有方窗、汉明窗和汉宁窗等,根据窗函数的频域特性,常采用汉明窗。[https://baike.baidu.com/item/%E7%AA%97%E5%87%BD%E6%95%B0/3497822
- 快速傅里叶变换
- 将上面的频谱通过Mel滤波器组得到Mel频谱;(通过Mel频谱,将线形的自然频谱转换为体现人类听觉特性的Mel频谱)https://www.jianshu.com/p/24044f4c3531
- 在Mel频谱上面进行倒谱分析(取对数,做逆变换,实际逆变换一般是通过DCT离散余弦变换来实现,取DCT后的第2个到第13个系数作为MFCC系数),获得Mel频率倒谱系数MFCC,这个MFCC就是这帧语音的特征;(倒谱分析,获得MFCC作为语音特征)
MFCC 实现
一开始尝试了 MATLAB,奈何找到的代码不太好用,报出没有melbankm这个函数的错误。简单搜索了一下说需要安装 MATLAB 的扩展工具包,下载安装后依旧没有该函数。当然扩展工具包里肯定是有 MFCC 提取的函数的,用 google 搜一下或者看一下 MATLAB 文档就好。但是既然这么麻烦,试试 Python 好了。
参考了 https://blog.csdn.net/seTaire/article/details/85707088
其中提到了两个库,一个是 Librosa, 一个是 python_speech_features 。后者于2017年停止更新,但是前者似乎还在更新(https://librosa.org/doc/latest/changelog.html,编写本博客时,最新版本为 2020-07-22 更新的 v0.8)。所以这里我还是使用了 Librosa。下面是安装命令。
1 | pip install librosa |
然后官网的安装指导还提到了一个细节。
ffmpeg
To fuel
audioreadwith more audio-decoding power, you can install ffmpeg which ships with many audio decoders. Note that conda users on Linux and OSX will have this installed by default; Windows users must install ffmpeg separately.OSX users can use homebrew to install ffmpeg by calling brew install ffmpeg or get a binary version from their website https://www.ffmpeg.org.
就是 Windows 用户为了支持更多音频格式,需要额外安装 ffmpeg。
https://www.ffmpeg.org/download.html
暂时没安装,不知道这个怎么与 librosa 配合,就还没有安装。
librosa 底层调用 ffmpeg 是使用的命令行界面。所以要先安装 ffmpeg,然后确保命令行的path等设置正确,能够在命令行直接打开ffmpeg。
我是在 https://ffmpeg.zeranoe.com/builds/ 下载的 Windows 的已编译版本。下载后为压缩包,本来以为是个 Installer,结果发现就是直接可用的。那么找个路径解压后,在 bin 目录添加 path 即可。
配置完了 ffmpeg,确定命令行可以直接启动后,再次尝试运行代码继续报错。
测试代码如下。
1 | import librosa |
报错信息如下。
1 | PS F:\> xxx F:\xxx\mfcc_librosa.py |
之后的尝试包括按照报错信息找到了 PySoundFile。但是这个 repo 已经是个空壳了,重命名到 SoundFIle 了,而无论是 PySoundFile亦或是 SoundFile 我都已经正常安装。但是依旧报错。
最后认输了。MATLAB 两行命令把格式从 m4a 转码成了 wav。
1 | [x,fs] = audioread('yyy.m4a'); |
转码成 wav 之后一切都正常了。大约用了几秒钟输出 MFCC 的内容。问题完美解决。
1 | PS F:\DolphinAttack> python F:\DolphinAttack\mfcc_librosa.py |
使用 matplotlib 绘图。
1 | import librosa |
输出结果如下图所示。
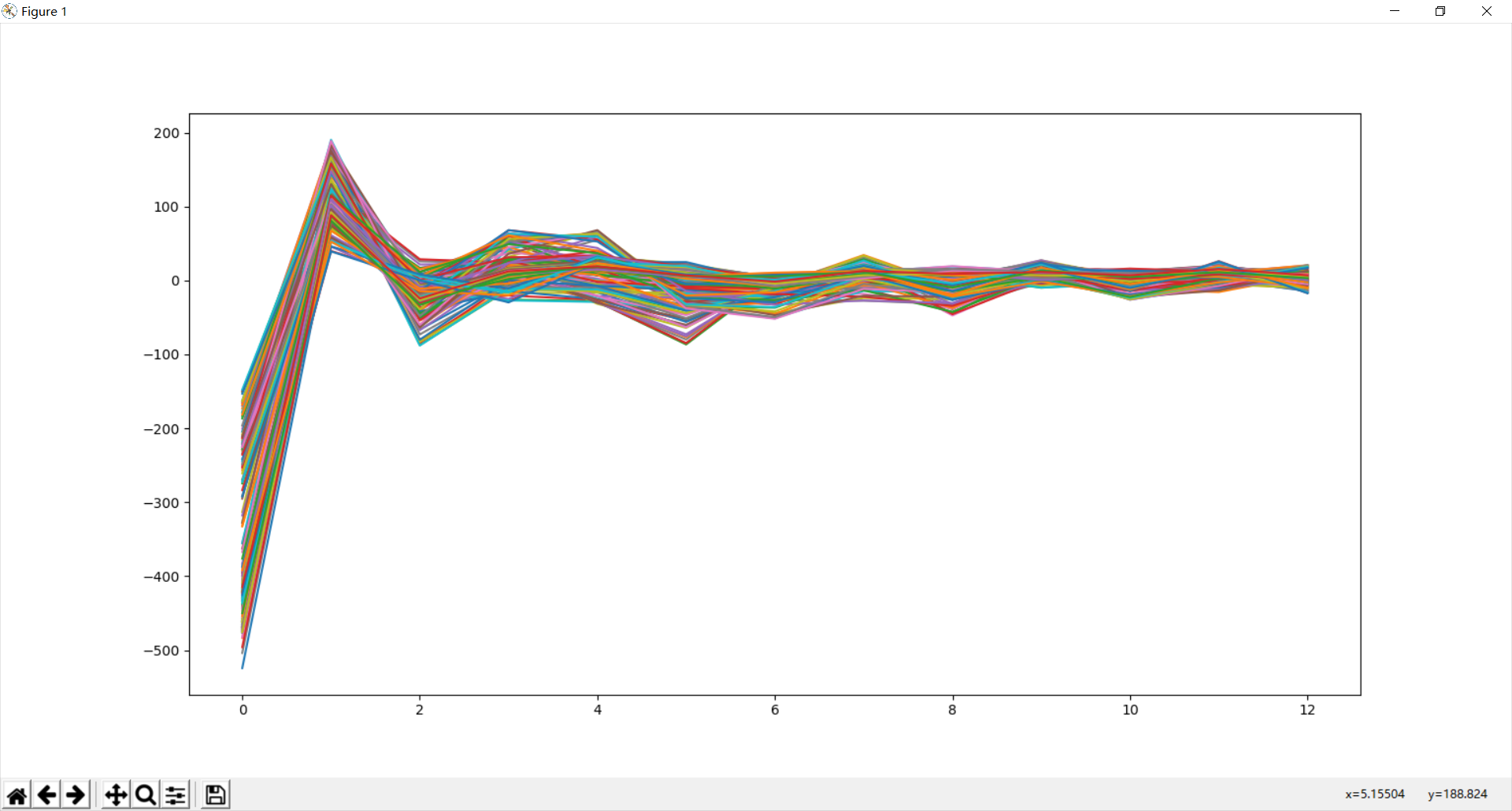
第一眼看上去,诶,和说好的不太一样啊,五颜六色的不太好看啊。验证了一下发现 MFCC 函数输出的是一个 13 * 234的二维数组,而13是传给 MFCC 函数的参数,表示每一帧提取多少个系数。而 234 则会因传入的音频而异,表示的是音频划分的帧数。也就是说,从纵向看,每列都是一帧的 MFCC 系数。但是现在对于相关应用的了解太浅了,不知道该怎么使用这个二维数组。
MATLAB 声音相关操作
https://www.cnblogs.com/BugsCreator/p/10270451.html AudioWrite 函数用法